Schnittstellen
kVASy Adressimport aus Tourendaten V2
Einführung
Dieses Dokument richtet sich an technische Anwender und Beratungsmitarbeiter und beschreibt die Konfiguration und Verwendung des kVASy Adressimports aus Tourendaten V2. V2 läuft parallel zur bestehenden V1-Variante. Sie können eine V1-Konfiguration belassen und V2 dort einsetzen, wo die Trennung zwischen Gruben- und Korrespondenzadresse benötigt wird.
Was ist neu gegenüber V1
- Trennung Gruben-/Korrespondenzadresse: Wenn die Kunden-Adresse (
Kunde_*) von der Grubenadresse (DZA_*) abweicht (Strasse, Hausnummer, Zusatzhausnummer, PLZ, Ort), legt V2 zusätzlich eine Korrespondenzadresse an und verknüpft sie überaddress.correspondence_address_idmit der Grube. - Update-Schlüssel ist
DZA_InvNr(nichtDZAPKwie in V1) und wird aufaddress.pit_numberabgelegt. Kundennummeralshostsystem_referenceauf Gruben- und Korrespondenzadresse — so bleiben beide Datensätze über das Quellsystem identifizierbar.- Neue optionale Config Tags:
pump_out/client/ident— Client für die Service-Rollepump_out.drainage/job_type/ident— Job-Typ für dierecurring_drainage_definition(DefaultAbfuhr; viele Bestandskunden setzenFäkalauftrag).
- Neuer Zähler
unchangedin der Job-Zusammenfassung: Zeilen, die verarbeitet wurden, aber zu keiner Datenänderung geführt haben. - Neue Adressspalte „Verwendung" zeigt auf einen Blick, ob ein Datensatz
Grube,KorrespondenzoderRechnungist (auch in der erweiterten Suche filterbar).
Funktionsumfang
V2 verarbeitet eine CSV-Datei und führt pro Zeile in genau dieser Reihenfolge aus:
- Gruben-Upsert anhand
DZA_InvNr. Vorhandene Grube → Update bei Abweichung, sonst keine Änderung. Nicht vorhanden → Insert. - Korrespondenz-Upsert (nur wenn nötig, siehe Wann entsteht eine Korrespondenzadresse?). Vorhandene Adresse mit gleicher
Kundennummerundpit_number IS NULLwird aktualisiert; sonst neu angelegt. - Verknüpfung der Grube mit der Korrespondenzadresse (
address.correspondence_address_id); ist keine Korrespondenz mehr nötig, wird die Verknüpfung entkoppelt (die Adresse bleibt erhalten). - Sekundärdaten nur bei neuen Gruben: Service-Provider (Kläranlage, Abwasserzweckverband, optional Abpumpunternehmen) und eine
recurring_drainage_definitionwerden ausschliesslich für neu angelegte Grubenadressen erzeugt — nie für Updates und nie für Korrespondenzadressen.
Zugriff
Die Import Job Definition für V2 wird beim Setup automatisch angelegt und liegt neben der V1.
So gelangen Sie zur V2-Konfiguration:
- Navigieren Sie zu Schnittstellen → Import-Job-Definition.
- Wählen Sie den Eintrag „kVASy Adressimport aus Tourenplanung V2".
- Direktlink:
/interface/import_job_definition/<id>(im obigen Screenshot Id3).
Fachliche Konfiguration
Die fachliche Konfiguration steuert, welche Stammdaten beim Import an die Grubenadresse angehängt werden. Sie erfolgt ausschliesslich über Configuration Tags (Key/Value-Paare) auf der V2 Import Job Definition.
Bevor Sie speichern, stellen Sie sicher, dass alle referenzierten Idents (Client, Artikel, Job-Typ) tatsächlich in der Datenbank existieren. Ein fehlender Ident bricht den Import mit einer eindeutigen Fehlermeldung ab (siehe Fehler nachverfolgen).
Hinweis: Ein Screenshot der Sektion „Configuration Tags" mit den V2-Werten wird hier ergänzt, sobald
config_tags.pngim Image-Ordner verfügbar ist.
Erforderliche Config Tags
| Config Tag | Wofür | Beispiel |
|---|---|---|
sewage_treatment_plant/client/ident | Client mit der Rolle „Kläranlage" auf neuen Gruben | WTAZV |
wastewater_association/client/ident | Client mit der Rolle „Abwasserzweckverband" auf neuen Gruben | WTAZV |
waste_material_id/ident | Artikel für recurring_drainage_definition.waste_material_id | Haushaltsabwasser |
Optionale Config Tags
| Config Tag | Wofür | Default / Beispiel |
|---|---|---|
pump_out/client/ident | Neu in V2 — Client mit der Rolle „Abpumpunternehmen" auf neuen Gruben | WTAZV |
drainage/job_type/ident | Neu in V2 — Job-Typ-Ident für die recurring_drainage_definition | Default: Abfuhr — Bestandskunden setzen häufig Fäkalauftrag |
DZA_WHGNR_PREFIX | Präfix, der vor den DZA_WHGNR-Wert gestellt wird, wenn der Wert dem Muster aus DZA_WHGNR_REGEX entspricht | Default: WHG (z. B. 3 → WHG 3) |
DZA_WHGNR_REGEX | Vollständiger regulärer Ausdruck, der entscheidet, ob der Präfix gesetzt wird | Default: \d+ (rein numerische Werte). Leer setzen, um den Präfix komplett zu deaktivieren. |
verbose | Erweiterte Debug-Logs im Backend einschalten | true / false (Default false) |
Wohnungsnummer (DZA_WHGNR → street_ext)
Die optionale Tourenplan-Spalte DZA_WHGNR (Spaltenindex BD) wird auf die Grubenadresse als address.street_ext (Beschriftung „Strasse Zusatz") übernommen. Der Wert wird vor dem Speichern getrimmt; ein leerer Wert lässt einen bereits vorhandenen Datenbankwert unverändert (kein Überschreiben mit Leer).
Verhalten der Präfix-Logik:
- Trifft der Wert auf
DZA_WHGNR_REGEXzu (Standard: rein numerisch), wirdDZA_WHGNR_PREFIXmit einem Leerzeichen vorangestellt — z. B.3→WHG 3. - Trifft er nicht zu (z. B.
EG-links), wird der getrimmte Wert ohne Präfix gespeichert. - Ist
DZA_WHGNR_REGEXleer, wird der Präfix nie angewandt.
V2 schreibt street_ext ausschliesslich auf die Grubenadresse, nicht auf die Korrespondenzadresse.
Wann entsteht eine Korrespondenzadresse?
Eine Korrespondenzadresse wird genau dann angelegt (oder aktualisiert), wenn mindestens eines der folgenden Felder zwischen Kunden- und Grubenadresse abweicht (Vergleich ist trim/lowercase-tolerant):
Kunde_Strasse↔DZA_StrasseKunde_Hausnummer↔DZA_HausnummerKunde_Zusatzhausnummer↔DZA_ZusatzhausnummerKunde_PLZ↔DZA_PLZKunde_Ort↔DZA_Ort
Die Korrespondenzadresse wird über die Kundennummer (in hostsystem_reference) gefunden bzw. aktualisiert. Pro Kundennummer existiert höchstens eine Korrespondenzadresse (deterministische Auswahl der niedrigsten Id, falls historisch mehrere vorliegen).
Stimmen sämtliche Felder bei einem späteren Re-Import wieder überein, bleibt die Korrespondenzadresse als Datensatz erhalten, lediglich die Verknüpfung address.correspondence_address_id der Grube wird auf NULL gesetzt (Zähler correspondence cleared).
Sekundärdaten — Invariante
Service-Provider und
recurring_drainage_definitionwerden ausschliesslich für neu angelegte Grubenadressen erzeugt.
- Updates an existierenden Gruben legen keine zusätzlichen Service-Provider an und ändern keine bestehende Regelentsorgung.
- Korrespondenzadressen erhalten niemals Service-Provider oder eine Regelentsorgung.
Dies entspricht dem Verhalten der V1-Variante.
Welche Felder werden immer auf die Grube übertragen?
Unabhängig davon, ob eine Korrespondenzadresse entsteht, werden bei jedem Import folgende Kunden-Felder auf die Grube synchronisiert:
| CSV-Feld(er) | Adress-Feld der Grube |
|---|---|
Kunde_Name1 | name |
Kunde_Name2 | name2 |
Kunde_Vorwahl + Kunde_Telefon | phone (zusammengesetzt als Vorwahl/Telefon) |
Kunde_Telefax | fax |
Kunde_eMail | email |
Pit-spezifische Felder (DZA_Strasse, DZA_PLZ, DZA_Ort, DZA_Anlagenart, DZA_Nutzinhalt, DZA_Personen, DZA_Wartung_Letzte, DZAPK, DZA_Bauart) werden ebenfalls auf die Grube übernommen.
Technische Konfiguration
Die technische Konfiguration legt fest, wie die CSV-Datei eingelesen wird. Sie ist identisch zu V1 und kann auf der Detailseite der Import Job Definition angepasst werden.
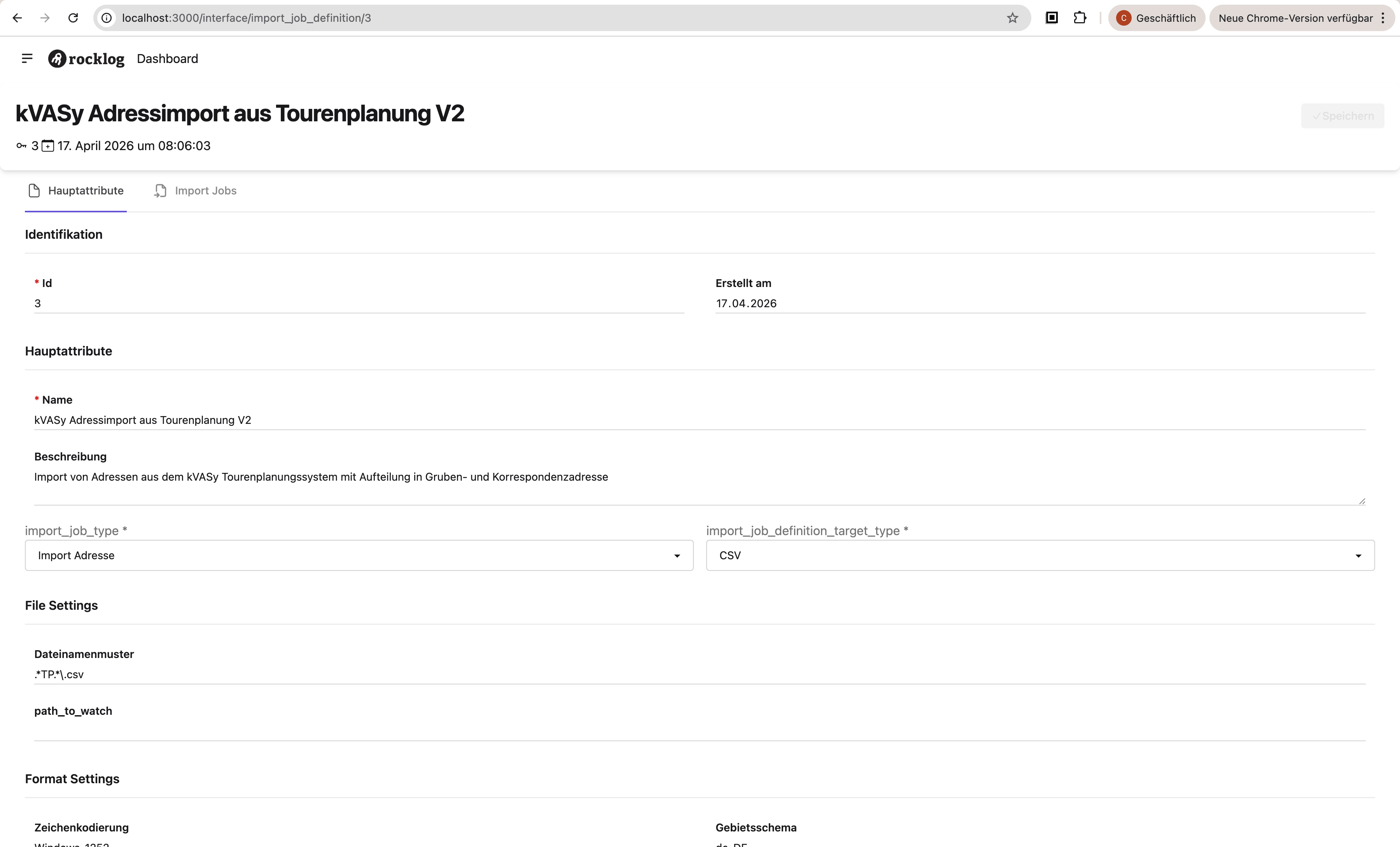
Hauptattribute
| Attribut | Wert |
|---|---|
| Name | kVASy Adressimport aus Tourenplanung V2 |
| Beschreibung | Import von Adressen aus dem kVASy Tourenplanungssystem mit Aufteilung in Gruben- und Korrespondenzadresse |
import_job_type | address |
import_job_definition_target_type | csv |
Dateinamenmuster | .*TP.*\.csv |
path_to_watch | NULL (nur manueller Upload) |
Format-Settings
| Attribut | Wert |
|---|---|
Encoding | Windows-1252 |
Separator | ; |
Quote | NULL (deaktiviert — kVASy-Exporte enthalten unescapte Anführungszeichen) |
Locale | de-DE |
CSV-Spalten
Mindestens benötigt:
| Spalte | Verwendung in V2 |
|---|---|
DZA_InvNr | Update-Schlüssel für die Grubenadresse (address.pit_number) — Pflicht; leere Zeilen werden gezählt als ignored |
Kundennummer | hostsystem_reference für Gruben- und Korrespondenzadresse |
Kunde_Name1, Kunde_Name2 | name, name2 (immer auf Grube übertragen) |
Kunde_Vorwahl, Kunde_Telefon | phone (als Vorwahl/Telefon zusammengesetzt, immer auf Grube übertragen) |
Kunde_Telefax, Kunde_eMail | fax, email (immer auf Grube übertragen) |
Kunde_Strasse, Kunde_Hausnummer, Kunde_Zusatzhausnummer, Kunde_PLZ, Kunde_Ort, Kunde_LKZ | Korrespondenzadresse (siehe Wann entsteht eine Korrespondenzadresse?) |
DZA_Strasse, DZA_Hausnummer, DZA_Zusatzhausnummer | werden zu street der Grube zusammengesetzt |
DZA_WHGNR | optional → street_ext der Grube; Präfix-Verhalten siehe Wohnungsnummer (DZA_WHGNR → street_ext) |
DZA_PLZ, DZA_Ort | zip, city der Grube |
DZA_Anlagenart | wird über type_of_pit/ident aufgelöst → address.type_of_pit_id |
DZA_Nutzinhalt, DZA_Personen, DZA_Wartung_Letzte, DZA_Entsorgungsmenge, DZAPK, DZA_Bauart | weitere Pit-Attribute |
DZA_Wartung_Zyklus | Eingabe für recurring_drainage_definition.cycle_months (nur bei neuen Gruben verwendet) |
Datenkonvertierung
- Datum: Erwartet
dd.MM.yyyy(auchd.M.yyyy; zweistellige Jahre werden als20yyinterpretiert). - Dezimal: Komma als Dezimaltrenner (
5,5→5.5). - Strasse:
DZA_Strasse + " " + DZA_Hausnummer + DZA_Zusatzhausnummer. - Telefon:
Kunde_Vorwahl + "/" + Kunde_Telefon. - Drainage-Zyklus:
1 / J→ 12 Monate (einmal pro Jahr)2 / J→ 6 Monate/ J→ 12 Monate/ K→ unbekannt (wird ignoriert)- reine Zahl → Anzahl Monate
Datei hochladen / Import starten
Der Import kann von zwei Stellen gestartet werden — am komfortabelsten direkt von der Adressliste.
Schritt 1 — Adressliste öffnen
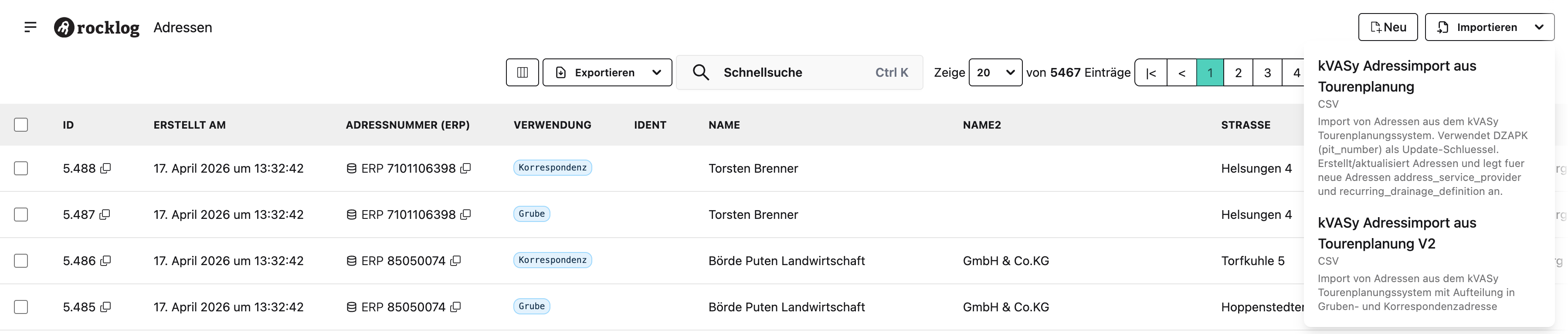
Das Dropdown „Importieren" zeigt alle für die Domäne address aktiven Import Job Definitionen — V1 und V2 erscheinen hier nebeneinander. In der Tabelle ist die neue Spalte „Verwendung" sichtbar mit Tags Grube, Korrespondenz und Rechnung.
Schritt 2 — V2 wählen und Datei hochladen
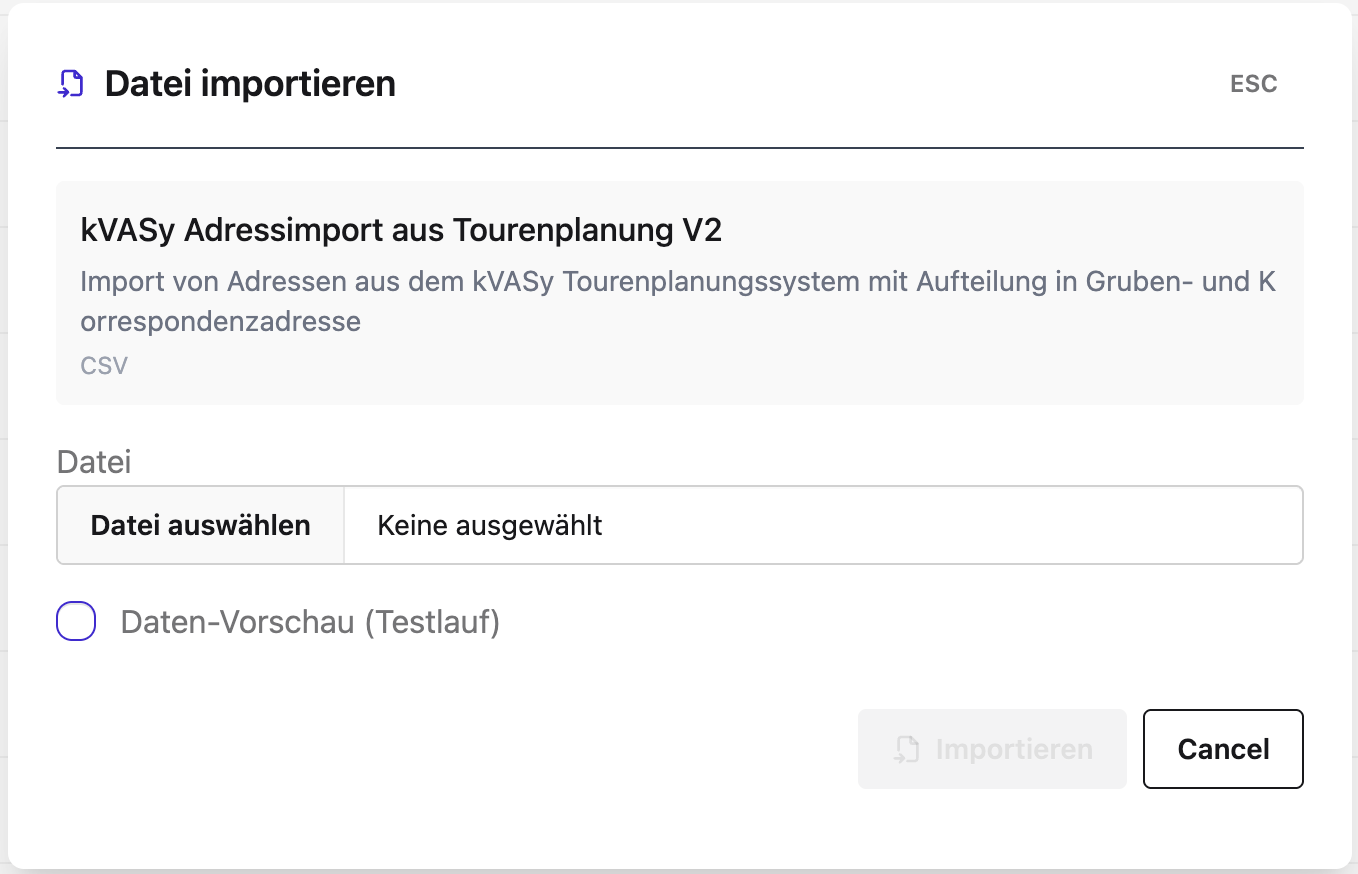
Im Dialog „Datei importieren":
- Datei auswählen — die Datei muss dem Muster
.*TP.*\.csventsprechen (also „TP" im Dateinamen tragen) und Windows-1252-codiert sein. - Daten-Vorschau (Testlauf) aktivieren, wenn die Datei vor dem produktiven Import nur validiert werden soll. Im Dry-Run werden keine Datensätze geschrieben, es wird lediglich geprüft, ob:
- die Pflichtspalten vorhanden sind,
- die referenzierten Stammdaten (Client/Artikel/Job-Typ) auflösbar sind,
- die Datei syntaktisch lesbar ist.
- Importieren klicken.
Schritt 3 — Status verfolgen
Nach dem Klick wird ein Import Job angelegt. Sie finden ihn unter Import-Job-Definition → V2-Detailseite → Tab „Import Jobs". Mögliche Statuswerte:
progress— wird gerade verarbeitet,done— abgeschlossen (auch wenn einzelne Zeilen Fehler hatten),failed— Abbruch vor der Zeilenverarbeitung (z. B. wegen fehlender Pflichtspalte oder unauflösbarem Config Tag).
Fehler nachverfolgen
Hinweis: Ein Screenshot des „Import Jobs"-Tabs mit der V2-Zusammenfassung wird hier ergänzt, sobald
import_jobs_tab.pngim Image-Ordner verfügbar ist.
Wo finde ich was?
Im Tab „Import Jobs" auf der V2-Detailseite stehen pro Lauf:
| Feld | Inhalt |
|---|---|
state | progress / done / failed |
msg | V2-Zusammenfassung — siehe nächste Tabelle |
error_msg | Top-Level-Fehler (bei failed) |
error_details | Liste pro fehlerhafter Zeile mit row, pit_number, kundennummer, error |
Die V2-Zusammenfassung (msg)
Beispiel:
Import V2 completed: 5 pit created, 2 pit updated, 4 correspondence created,
1 correspondence updated, 1 correspondence cleared, 3 unchanged, 1 ignored,
0 failed (total: 12 rows)
| Zähler | Bedeutung |
|---|---|
pit created | Neue Grubenadresse angelegt (inkl. Service-Provider und Regelentsorgung) |
pit updated | Existierende Grube wegen Attributänderung aktualisiert |
correspondence created | Neue Korrespondenzadresse angelegt und mit der Grube verknüpft |
correspondence updated | Existierende Korrespondenzadresse aktualisiert |
correspondence cleared | Verknüpfung der Grube zur Korrespondenz auf NULL gesetzt (Adresse bleibt erhalten) |
unchanged | Zeile verarbeitet, aber keine Änderung an Grube oder Korrespondenz |
ignored | Zeile übersprungen, weil DZA_InvNr leer war |
failed | Zeile warf eine Exception — Details unter error_details |
Invariante: pit created + pit updated + correspondence created + correspondence updated + correspondence cleared + unchanged + ignored + failed = total (jede Zeile fällt in genau einen Bucket; Korrespondenz-Zähler addieren sich zusätzlich, weil eine Zeile sowohl Grube als auch Korrespondenz berühren kann).
Häufige Fehlerbilder
| Symptom | Ursache | Lösung |
|---|---|---|
Required column 'DZA_InvNr' not found in CSV | Header heisst anders / V1-Datei (DZAPK) verwendet | Header korrigieren oder V1-Definition verwenden |
Client with ident 'WTAZV' not found | Client fehlt in den Stammdaten | Client anlegen oder Config Tag korrigieren |
Article with ident 'Haushaltsabwasser' not found | Artikel fehlt | Artikel anlegen oder waste_material_id/ident korrigieren |
Job type 'Abfuhr' not found (drainage/job_type/ident) | Default-Job-Typ existiert nicht in der Installation | Config Tag drainage/job_type/ident auf einen vorhandenen Job-Typ setzen (häufig Fäkalauftrag) |
0 pit created … X ignored obwohl alle Zeilen DZA_InvNr haben | Backend-Runtime nicht neu kompiliert nach Code-Änderung | Runtime Namespace neu kompilieren (POST /v1/runtime_namespace/<id>/compile) und Import erneut starten |
0 pit created, 0 pit updated, … X unchanged | Identischer Re-Import — kein Bug, sondern erwartet | Bei Änderungserwartung Quelldaten gegen Datenbank-Stand prüfen |
| Korrespondenzadresse fehlt, obwohl Kunden- und Grubenadresse augenscheinlich abweichen | Vergleich erfolgt trim/lowercase-tolerant — reine Whitespace- oder Gross-/Kleinschreibungs-Differenzen werden als gleich gewertet | Quelldaten prüfen; ggf. tatsächliche Differenz herstellen |
| Service-Provider werden nicht erstellt, obwohl Config Tag gesetzt ist | Adresse existierte bereits, V2 erzeugt Service-Provider nur für neue Gruben | Falls nachträglich erforderlich: Service-Provider manuell pflegen oder die Adresse vorher löschen lassen |
Tiefergehende Diagnose
verbose=trueals Config Tag setzen und den Import erneut starten — die Backend-Logs enthalten dann pro Zeile detaillierte Informationen zur Auflösung und zum Vergleich.- Beim Verdacht auf Datentyp-Probleme (Datum, Dezimal): die betroffenen Spalten in einem Texteditor prüfen — kVASy verwendet
dd.MM.yyyyund,als Dezimaltrenner. - Cross-Check über die neue Adressliste: Filter „Verwendung = Grube" / „… = Korrespondenz" in der erweiterten Suche, um zu kontrollieren, welche Datensätze tatsächlich angelegt wurden.
Beispiel-Konfiguration & -Resultat
Vollständige Config Tags
sewage_treatment_plant/client/ident=WTAZV
wastewater_association/client/ident=WTAZV
pump_out/client/ident=WTAZV
waste_material_id/ident=Haushaltsabwasser
drainage/job_type/ident=Fäkalauftrag
verbose=false
Beispiel A — Kunde und Grube unterschiedlich
CSV-Zeile (Auszug):
Kundennummer=K001
Kunde_Name1=Mustermann GmbH
Kunde_Strasse=Büroweg
Kunde_Hausnummer=10
Kunde_PLZ=14000
Kunde_Ort=Hauptstadt
Kunde_Vorwahl=030
Kunde_Telefon=1234567
DZA_InvNr=ASG-12345
DZA_Anlagenart=abflusslose Sammelgrube
DZA_Strasse=Hauptstraße
DZA_Hausnummer=42
DZA_PLZ=12345
DZA_Ort=Musterstadt
DZA_Wartung_Zyklus=1 / J
Resultat:
- Grubenadresse —
pit_number=ASG-12345,hostsystem_reference=K001,name=Mustermann GmbH,street=Hauptstraße 42,phone=030/1234567,correspondence_address_id→ Id der unten erzeugten Korrespondenz. - Korrespondenzadresse (neu, weil Kunden- ≠ Grubenadresse) —
hostsystem_reference=K001,name=Mustermann GmbH,street=Büroweg 10,pit_number IS NULL. - Service-Provider auf der Grube:
sewage_treatment_plant,wastewater_association,pump_out— alle mit ClientWTAZV. - Regelentsorgung auf der Grube:
cycle_months=12,job_type=Fäkalauftrag,waste_material=Haushaltsabwasser. - Zusammenfassung (für 1 Zeile):
1 pit created, 1 correspondence created, 0 unchanged, 0 ignored, 0 failed (total: 1 rows).
Beispiel B — Kunde und Grube identisch
Bei gleicher Kunden- und Grubenadresse (z. B. Eigenheim) entfällt die Korrespondenzadresse:
- Grubenadresse wird wie oben angelegt.
address.correspondence_address_idbleibtNULL.- Service-Provider und Regelentsorgung werden ebenfalls erzeugt.
- Zusammenfassung:
1 pit created, 0 correspondence created, 0 unchanged, 0 ignored, 0 failed (total: 1 rows).
Beispiel C — Re-Import ohne Änderung
Wird die identische Datei nochmals importiert:
- Zusammenfassung:
0 pit created, 0 pit updated, 0 correspondence created, 0 correspondence updated, 0 correspondence cleared, N unchanged, 0 ignored, 0 failed (total: N rows). - Es entstehen keine zusätzlichen Datensätze; vorhandene Service-Provider bleiben unverändert.